


f.45 Fan-Tailed Cuckoo [Cacomantis flabelliformis, male], Drawings of birds chiefly from Australia, 1791-1792
Dans l’article Sérendipité et innovation, nous avons étudié comment l’usage de l’intelligence artificielle pour mener les recherches sur internet peut apparaitre comme un frein à la sérendipité, mais aussi comment l’intelligence artificielle générative en général peut se révéler être un bouclier envers les idées nouvelles et la créativité, noyant l’innovation dans un flot de données formant un consensus statistique et modélisant une pensée, un savoir, une culture commune majoritaire.
Nous découvrons aujourd’hui comment cet état, loin d’être une prédiction pessimiste, est bel et bien déjà présent et en développement ; en effet, plusieurs études et analyses nous montrent comment les contenus rédigés, créés ou assistés par intelligence artificielle inondent déjà aussi bien internet que la recherche scientifique, tandis que différents moteurs de recherche, dont Google, commencent à imposer leur « agent conversationnel » comme porte d’entrée à la recherche sur internet. En mars 2025, ce monde numérique dans lequel l’intelligence artificielle rédige le contenu disponible, mais est aussi la porte d’accès à ce « savoir », est déjà là.
Déjà en avril 2024, une équipe de chercheurs de l’université de Stanford constate que de 5 à 17,5 % des articles scientifiques ont été modifiés ou rédigés en utilisant l’intelligence artificielle1, dans une proportion dépendant des domaines de recherche, les articles utilisant le moins les modèles de langage étant ceux traitant de sciences naturelles, de physique et de mathématiques, et ceux en usant le plus ceux concernant les sciences informatiques, parmi un peu plus de 950 000 articles étudiés2. Cet usage des modèles de langage semblait se limiter à environ 2,5 % des articles avant début 2023 et la sortie de ChatGPT, mais est en constante augmentation depuis.
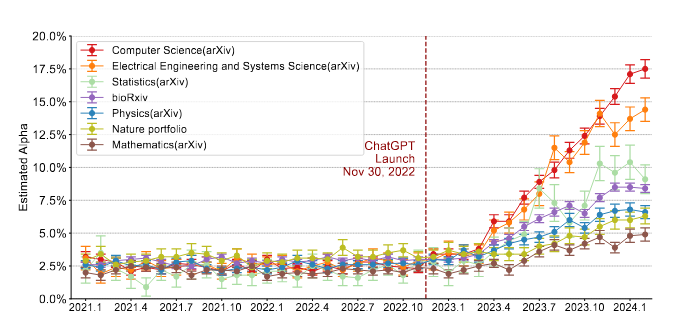
L’usage de l’intelligence artificielle dans les articles scientifiques parait être notoirement plus élevé parmi les auteurs qui postent plus régulièrement des articles en pré-publication (non relus par les pairs), ceux dans les domaines de recherche les plus fréquents, et les articles plutôt courts.
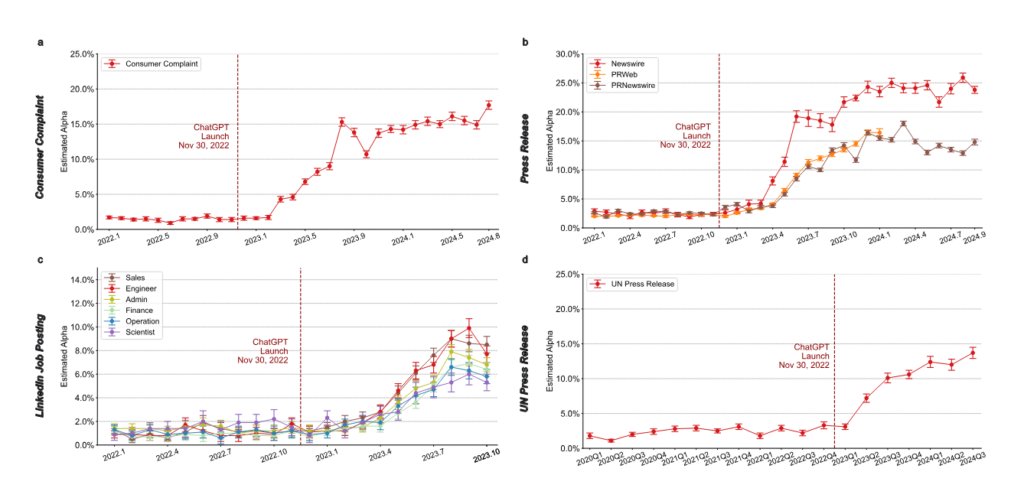
Si l’usage de l’intelligence artificielle dans les articles scientifiques est un bon exemple, symptomatique, de l’évolution de la société dans sa manière d’étendre la connaissance, cette tendance ne s’y limite pas et se retrouve en fait dans tout ce qui fait notre culture. Une équipe semblable a appliqué le même genre d’analyse, arrivant aux mêmes conclusions3, sur un énorme corpus de plaintes de consommateurs et consommatrices, de communiqués de presse, d’offres d’emploi (sur Linkedin) et même de communiqués des Nations Unies, où l’usage de modèles de langages tient une part non négligeable, et, bien que se tassant un peu, toujours en augmentation aussi.
Archétype du partage des connaissances en ligne, l’encyclopédie Wikipédia elle-même n’est pas épargnée : selon une équipe de l’université de Princeton4, ce serait jusqu’à un sur vingt nouveaux articles en 2024 qui auraient utilisé l’intelligence artificielle. Les chercheurs notent par ailleurs que les articles en question sont typiquement de moins bonne qualité et souvent auto-promotionnels ou partiaux quand ils portent sur des sujets à controverse. Des défauts qui préexistent à l’usage de l’I.A. mais que son usage semble favoriser.
Les informations publiées chaque jour sont aussi sujettes à cette tendance ; sur les plus de 850 000 articles publiés par plus de 26 000 éditeurs le 1er juillet 2024, presque 60 000, quasiment 7 %, étaient écrits par une intelligence artificielle5, avec des disparités selon les pays, 8 % en France par exemple, 16 % en Colombie et jusqu’à plus de 30 % au Ghana. La plupart de ces articles ont pour but de véhiculer des publicités ou des contenus sponsorisés, ce qui peut expliquer la disparité dans les proportions en fonction des domaines, montant à 13 % pour les articles concernant la beauté et quasiment 14 % pour les technologies. Une part de ces articles sert aussi la désinformation ou des arnaques diverses.
Tous les domaines du savoir paraissent ainsi touchés, tout ce qui fait notre culture commence à subir la pollution des générations par intelligence artificielle. Il est tout à fait légitime ici de parler de pollution, quand on constate que les humains préfèrent largement lire du contenu écrit par d’autres humains6, ou que les réponses apportées par des modèles de langage peuvent poser divers problèmes dans plus de 50 % des informations, dont 19 % d’erreurs factuelles ou encore 13 % de fausses citations7.
Nous ne parlons ici que de données textuelles, les études apportant des données mesurées portant plutôt sur le texte que sur l’image ou la vidéo, mais il est tout à fait raisonnable de penser que la part d’autres médias générés par intelligence artificielle sur internet est aussi importante, dans le même ordre de grandeur.
Cette omniprésence de l’intelligence artificielle ne pose d’ailleurs pas que des problèmes sur les connaissances, mais même parfois de dysfonctionnements d’internet. Des serveurs, en particulier des dépôts de code open-source, ou des plateformes de banque d’images, ont déjà pu être bloqués en raison de vagues d’aspiration du contenu par des robots servant à la collecte des données pour des intelligences artificielles8, usant de diverses techniques de contournement des règles et de la sécurité des serveurs, et pouvant aller jusqu’à forcer les administrateurs à bloquer les connexions de pays entiers pour limiter la casse. Il apparait ainsi que de tels robots peuvent représenter plus de 90 % du trafic. Les services les plus impactés étant justement ceux qui proposent un accès libre à la connaissance et la culture, comme le code open source mais aussi Wikimedia Commons9, la plateforme hébergeant une vaste quantité de contenus multimédia notamment utilisés sur Wikipedia.
L’intelligence artificielle agit comme une espèce parasite développant sa propre culture via la génération de son propre contenu, choisi, halluciné et biaisé. Son propre univers se dilue alors dans la culture humaine, l’I.A. naviguant dans le contenu disponible sur internet et y mélangeant le sien ; cette culture propre à l’I.A., qui ne nous intéresse pas, se mélange à notre propre culture et vient la polluer, la dévaloriser, et en amplifier les biais. Il devient urgent de limiter aussi bien la génération des contenus par intelligence artificielle que l’accès de ses robots à internet, afin de sauvegarder aussi bien l’accès à la connaissance que l’innovation et la créativité.
- Mapping the Increasing Use of LLMs in Scientific Papers, pré-publication,
arXiv:2404.01268↩︎ - L’étude porte sur les articles en prépublication (non relus par les pairs) d’arXiv et bioRxiv, ainsi que les articles Nature. ↩︎
- The Widespread Adoption of Large Language Model-Assisted Writing Across Society, pré-publication,
arXiv:2502.09747↩︎ - The Rise of AI-Generated Content in Wikipedia,
arXiv:2410.08044↩︎ - 60,000 AI-generated news articles are published every day ↩︎
- AI vs Human: Who Writes Better Blogs That Get More Traffic? ↩︎
- Groundbreaking BBC research shows issues with over half the answers from Artificial Intelligence (AI) assistants ↩︎
- Open source devs say AI crawlers dominate traffic, forcing blocks on entire countries
Voir aussi ce post du PDG de Panther Media (une agence de banque de photos) qui explique comment l’impact des robots aspirant le contenu se chiffre en milliers de dollars mensuels, et peut conduire à devoir bloquer l’accès à des zones géographiques entières. ↩︎ - AI crawlers cause Wikimedia Commons bandwidth demands to surge 50%, Techcrunch ↩︎


Laisser un commentaire